
词法分析器/语法分析器
编译原理在理论上往往让人望而却步。这边准备跟着教程先从实践入门。先从手写的递归下降进行入门。
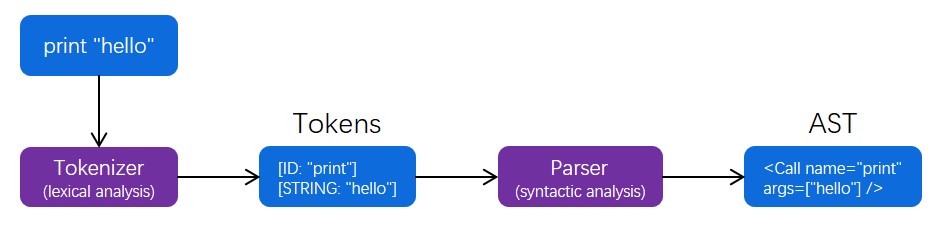
如图 1 所示,我们先大致了解编译器前端的工作流程。
1. 源代码:最先输入的是源码。如图是 `print("hello")` 。
2. 词法分析器:代码首先被送入词法分析器。词法分析器的任务是把输入的代码分解成一系列的 token。在图中,"print" 被识别为标识符;"hello" 被识别为字符串。
3. 语法分析器:接下来,这些 token 被送入语法分析器。语法分析器根据这些 token 构建出抽象语法树,即 AST。在图中,创建了一个“函数调用”节点,节点名称是 "print",参数是 "hello"。
理论不多说,我们先上代码。本章的代码记录在 Commit bf01654。
代码清单 1 是一个最简单的解析器,它只能处理仅含数字的字符串,并将其转换为 AST 节点。
- class Parser:
- def parse(self, string):
- """
- Parse a string into AST
- """
- self._string = string
- return self.Program()
- def Program(self):
- """
- Main entry point
- Program
- : NumericLiteral
- ;
- """
- return self.NumericLiteral()
- def NumericLiteral(self):
- """
- NumericLiteral
- : NUMBER
- ;
- """
- return {
- "type": "NumericLiteral",
- "value": int(self._string),
- }
注释里显示的是 BNF(巴科斯-诺尔范式),一种用于表示上下文无关文法的符号系统。这边写的规则是,Program 由一个 NumericLiteral 非终结符构成。NumericLiteral 由 NUMBER 终结符构成。即,现在我们的程序文本只能是数字。
在文法中,非终结符是那些可以被进一步分解成其他非终结符或终结符的符号。
终结符是文法的基本单元,不能被进一步分解。
最后,如代码清单 2 所示,我们写测试程序进行调用验证。
- import json
- from rd_parser import Parser
- # 实例化 Parser
- parser = Parser()
- # 定义输入程序
- program = '42'
- # 解析生成 AST
- ast = parser.parse(program)
- # 打印结果
- print(json.dumps(ast, indent=2))
可以看到程序能按预期打印。
- {
- "type": "NumericLiteral",
- "value": 42
- }