
正则表达式
在上一节中,我们引入了词法分析器,并实现了数字和字符串字面量的提取。但是我们目前是手动进行匹配解析的。面对后续越来越多的情况,解析会显得繁杂。
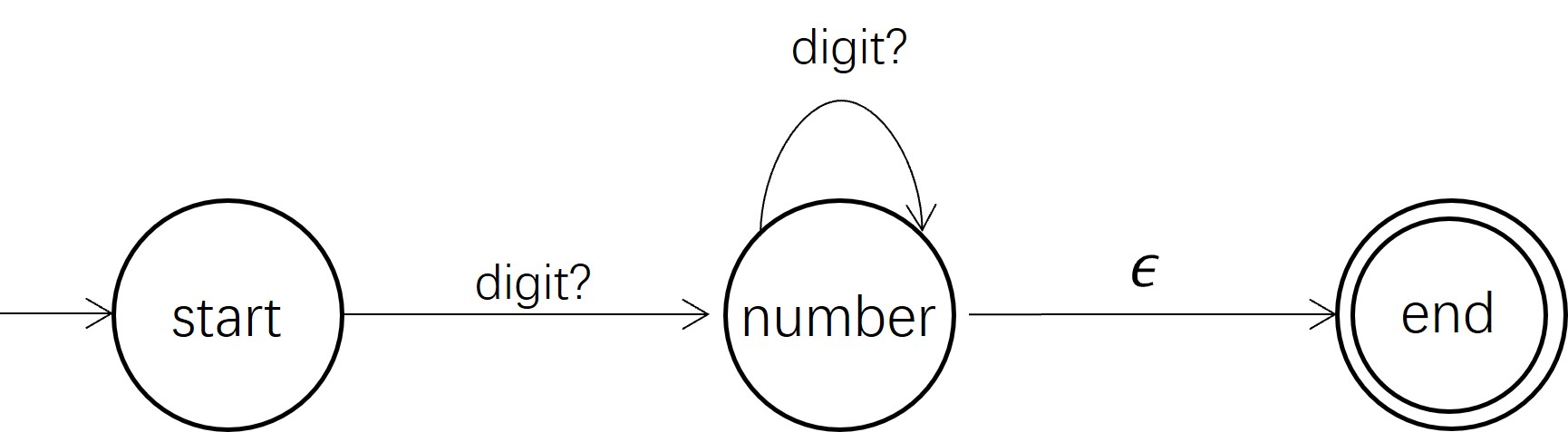
这已经是一个解决了的问题,有状态机相关的一套理论。比如数字的解析,对应于如图 1 所示的状态机。进一步,正则表达式描述可以生成对应模式的状态机。
所以,如代码清单 1 所示,我们将之前的数字和字符串提取过程,修改为使用正则表达式进行匹配。
- class Tokenizer {
- getNextToken() {
- if (!this.hasMoreTokens()) {
- return null;
- }
- const string = this._string.slice(this._cursor);
- // Numbers: \d+
- let matched = /^\d+/.exec(string);
- if (matched !== null) {
- this._cursor += matched[0].length;
- return {
- type: 'NUMBER',
- value: matched[0],
- };
- }
- // String
- matched = /"[^"]*"/.exec(string);
- if (matched !== null) {
- this._cursor += matched[0].length;
- return {
- type: 'STRING',
- value: matched[0],
- };
- }
- return null;
- }
- }
这个过程还能进一步“抽象”,我们只要指定 token 对应的正则表达式,因为匹配逻辑是通用的。如代码清单 2 所示,我们定义了词法单元的 Spec 数组。词法解析过程就是,依次尝试匹配 Spec 里定义的规范,只要匹配了就返回 token 信息,否则接着后续尝试。都匹配不上的话,则抛出异常。
我们可以看到这套逻辑很好用,因为我们很轻松的添加了字符串的另一种形式(第 10 行):使用单引号包围。
- /**
- * Tokenizer spec.
- */
- const Spec = [
- // Numbers:
- [/^\d+/, 'NUMBER'],
- // Strings:
- [/^"[^"]*"/, 'STRING'],
- [/^'[^']*'/, 'STRING'],
- ];
- class Tokenizer {
- getNextToken() {
- if (!this.hasMoreTokens()) {
- return null;
- }
- const string = this._string.slice(this._cursor);
- for (const [regexp, tokenType] of Spec) {
- const tokenValue = this._match(regexp, string);
- if (tokenValue === null)
- continue;
- return {
- type: tokenType,
- value: tokenValue,
- };
- }
- throw new SyntaxError(`Unexpected token: "${string[0]}"`);
- }
- _match(regexp, string) {
- const matched = regexp.exec(string);
- if (matched === null)
- return null;
- this._cursor += matched[0].length;
- return matched[0];
- }
- }
在目前的基础上,我们继续增加空白符的跳过。如代码清单 3 的第 31 行所示,如果我们匹配上空白符,则跳过这些字符,匹配后续满足的 token。
递归的写法,看着逻辑会更加清晰。写成“内部”的 while 循环也是可以的。
- /**
- * Tokenizer spec.
- */
- const Spec = [
- // Whitespace:
- [/^\s+/, null],
- // Numbers:
- [/^\d+/, 'NUMBER'],
- // Strings:
- [/^"[^"]*"/, 'STRING'],
- [/^'[^']*'/, 'STRING'],
- ];
- class Tokenizer {
- getNextToken() {
- if (!this.hasMoreTokens()) {
- return null;
- }
- const string = this._string.slice(this._cursor);
- for (const [regexp, tokenType] of Spec) {
- const tokenValue = this._match(regexp, string);
- if (tokenValue === null)
- continue;
- if (tokenType === null)
- return this.getNextToken();
- return {
- type: tokenType,
- value: tokenValue,
- };
- }
- throw new SyntaxError(`Unexpected token: "${string[0]}"`);
- }
- }
我们可以用以下测试用例检查一下流程,可以看到字符串前的空白符都如预期跳过了。当然,字符串里的空白符肯定是不受影响的。
- const program = ` " Hello world " `;
作为实验,代码中的注释信息,我们也不想保留。我们继续添加注释的正则表达式。如代码清单 4 所示,我们添加单行注释和多行注释的正则表达式。
多行注释需要跨行匹配,而且是非贪婪匹配。
- /**
- * Tokenizer spec.
- */
- const Spec = [
- // Whitespace:
- [/^\s+/, null],
- // Single-line comments:
- [/^\/\/.*/, null],
- // Multi-line comments:
- [/^\/\*[\s\S]*?\*\//, null],
- // Numbers:
- [/^\d+/, 'NUMBER'],
- // Strings:
- [/^"[^"]*"/, 'STRING'],
- [/^'[^']*'/, 'STRING'],
- ];
可以用以下测试用例验证单行注释和多行注释。
- const program = `
- // Number:
- 42
- `;
- const program = `
- /**
- * Documentation comment:
- */
- 42
- `;