
线程参数实践
在上一篇文章中,我们已经学习了线程配置的相关变量:threadIdx、blockIdx、blockDim 和 gridDim。在本篇文章中,我们通过多个“数组寻址”示例,进一步了解和巩固线程参数的使用。
1. 一维访问
如图 1 所示,是最简单的情形,只有一个 block。我们可以直接用 threadIdx.x 来索引数组。
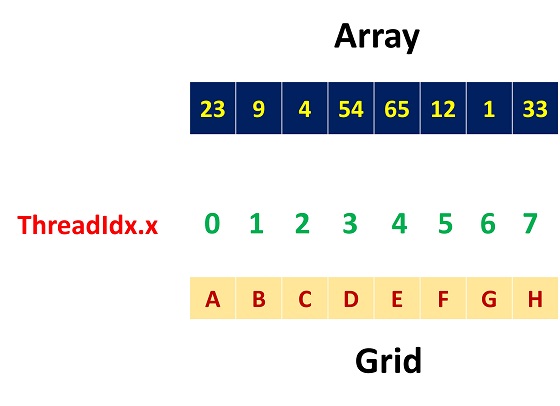
代码清单 1 是访问示例,我们将各个线程访问的数据进行打印。
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include <stdio.h>
- #include <vector>
- __global__ void unique_idx_calc_threadIdx(int* input)
- {
- int tid = threadIdx.x;
- printf("id=%d, value=%d\n", tid, input[tid]);
- }
- int main()
- {
- std::vector<int> h_data = {23, 9, 4, 53, 65, 12, 1, 33};
- int array_size = h_data.size();
- int array_byte_size = sizeof(int) * array_size;
- for (int i = 0; i < array_size; i++)
- printf("%d ", h_data[i]);
- printf("\n\n");
- int* d_data;
- cudaMalloc(&d_data, array_byte_size);
- cudaMemcpy(d_data, h_data.data(), array_byte_size, cudaMemcpyHostToDevice);
- dim3 block(8);
- dim3 grid(1);
- unique_idx_calc_threadIdx << < grid, block >> > (d_data);
- cudaDeviceSynchronize();
- cudaDeviceReset();
- return 0;
- }
核对打印结果,可以看到数组的各个元素都如预期访问到了。
- 23 9 4 53 65 12 1 33
- id=0, value=23
- id=1, value=9
- id=2, value=4
- id=3, value=53
- id=4, value=65
- id=5, value=12
- id=6, value=1
- id=7, value=33
2. 一维访问(多个 block)
图 2 也是一维情况,不过变为两个 block 运行。现在单凭 threadIdx.x 无法访问数组的全部内容,因为两个 block 的 threadIdx.x 范围都是一样的,都是 0 到 3。
这时候,我们可以利用上 blockIdx.x,乘上 block 的规模,此处是 blockDim.x。就能得到当前 thread 所在 block 的偏移。即最终的索引是:
blockIdx.x * blockDim.x + threadIdx.x。
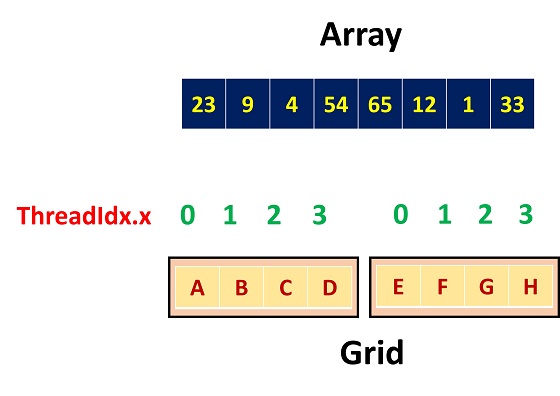
代码清单 2 是访问示例,我们更换了启动配置和索引方式。
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include <stdio.h>
- #include <vector>
- __global__ void unique_gid_calculation(int* input)
- {
- int gid = blockIdx.x * blockDim.x + threadIdx.x;
- printf("id=%d, blockIdx.x=%d, value=%d\n", gid, blockIdx.x, input[gid]);
- }
- int main()
- {
- std::vector<int> h_data = {23, 9, 4, 53, 65, 12, 1, 33};
- int array_size = h_data.size();
- int array_byte_size = sizeof(int) * array_size;
- for (int i = 0; i < array_size; i++)
- printf("%d ", h_data[i]);
- printf("\n\n");
- int* d_data;
- cudaMalloc(&d_data, array_byte_size);
- cudaMemcpy(d_data, h_data.data(), array_byte_size, cudaMemcpyHostToDevice);
- dim3 block(4);
- dim3 grid(2);
- unique_gid_calculation << < grid, block >> > (d_data);
- cudaDeviceSynchronize();
- cudaDeviceReset();
- return 0;
- }
核对打印结果,可以看到,基于所在 block 的 index,加上偏移后,能正确访问到每个数组元素。
- 23 9 4 53 65 12 1 33
- id=0, blockIdx.x=0, value=23
- id=1, blockIdx.x=0, value=9
- id=2, blockIdx.x=0, value=4
- id=3, blockIdx.x=0, value=53
- id=4, blockIdx.x=1, value=65
- id=5, blockIdx.x=1, value=12
- id=6, blockIdx.x=1, value=1
- id=7, blockIdx.x=1, value=33
3. 二维访问
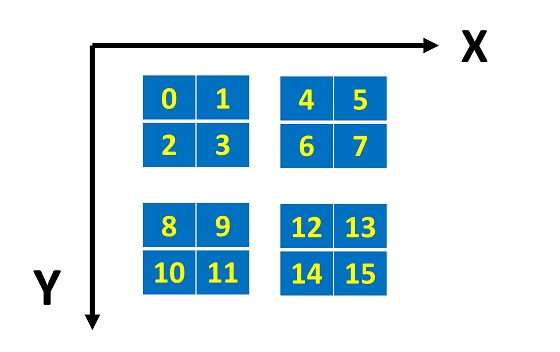
如图 3 所示,我们现在考虑 grid 是二维的情况。同样在列上,我们要加上偏移 blockIdx.x * blockDim.x。但是现在是二维情况,还要加上行上的偏移 blockIdx.y * gridDim.x * blockDim.x。
所以,最终的索引是:
blockIdx.y * gridDim.x * blockDim.x
+ blockIdx.x * blockDim.x
+ threadIdx.x
代码清单 3 是访问示例。我们将启动配置设置为和图 3 一致:grid 规模是 2x2,block 规模是 4x1。数据也增加到 16 个。
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include <stdio.h>
- #include <vector>
- __global__ void unique_gid_calculation_2d(int* input)
- {
- int gid = blockIdx.y * gridDim.x * blockDim.x +
- blockIdx.x * blockDim.x + threadIdx.x;
- printf("id=%d, blockIdx.x=%d, blockIdx.y=%d, value=%d\n", gid, blockIdx.x, blockIdx.y, input[gid]);
- }
- int main()
- {
- std::vector<int> h_data = {23, 9, 4, 53, 65, 12, 1, 33, 22, 43, 56, 4, 76, 81, 94, 32};
- int array_size = h_data.size();
- int array_byte_size = sizeof(int) * array_size;
- for (int i = 0; i < array_size; i++)
- printf("%d ", h_data[i]);
- printf("\n\n");
- int* d_data;
- cudaMalloc(&d_data, array_byte_size);
- cudaMemcpy(d_data, h_data.data(), array_byte_size, cudaMemcpyHostToDevice);
- dim3 block(4);
- dim3 grid(2, 2);
- unique_gid_calculation_2d << < grid, block >> > (d_data);
- cudaDeviceSynchronize();
- cudaDeviceReset();
- return 0;
- }
核对打印结果,可以看到索引正确。
- 23 9 4 53 65 12 1 33 22 43 56 4 76 81 94 32
- id=0, blockIdx.x=0, blockIdx.y=0, value=23
- id=1, blockIdx.x=0, blockIdx.y=0, value=9
- id=2, blockIdx.x=0, blockIdx.y=0, value=4
- id=3, blockIdx.x=0, blockIdx.y=0, value=53
- id=12, blockIdx.x=1, blockIdx.y=1, value=76
- id=13, blockIdx.x=1, blockIdx.y=1, value=81
- id=14, blockIdx.x=1, blockIdx.y=1, value=94
- id=15, blockIdx.x=1, blockIdx.y=1, value=32
- id=8, blockIdx.x=0, blockIdx.y=1, value=22
- id=9, blockIdx.x=0, blockIdx.y=1, value=43
- id=10, blockIdx.x=0, blockIdx.y=1, value=56
- id=11, blockIdx.x=0, blockIdx.y=1, value=4
- id=4, blockIdx.x=1, blockIdx.y=0, value=65
- id=5, blockIdx.x=1, blockIdx.y=0, value=12
- id=6, blockIdx.x=1, blockIdx.y=0, value=1
- id=7, blockIdx.x=1, blockIdx.y=0, value=33
4. 二维访问(二维的 block)
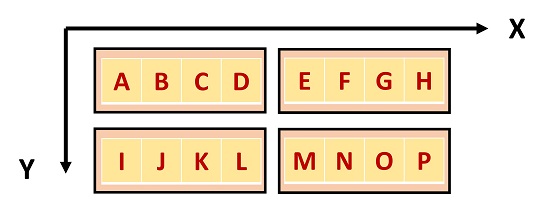
我们看本篇文章的最后一个示例。如图 4 所示,grid 布局是二维的,block 布局也是二维。
此时,block 内的索引需要变更为 threadIdx.y * blockDim.x + threadIdx.x。
和二维访问一样,先加上列上的偏移 blockIdx.x * blockDim.x * blockDim.y。
再加上行上的偏移 blockIdx.y * gridDim.x * blockDim.x * blockDim.y。
代码清单 4 是访问示例。可以直接写出寻址公式,但是代码里还是详细拆解了各个步骤,更易读。
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include <stdio.h>
- #include <vector>
- __global__ void unique_gid_calculation_2d_2d(int* input)
- {
- #if 0
- int gid = threadIdx.y * blockDim.x + threadIdx.x +
- blockIdx.x * blockDim.x * blockDim.y +
- blockIdx.y * gridDim.x * blockDim.x * blockDim.y;
- #endif
- int tid = threadIdx.y * blockDim.x + threadIdx.x;
- int num_threads_in_a_block = blockDim.x * blockDim.y;
- int block_offset = blockIdx.x * num_threads_in_a_block;
- int num_threads_in_a_row = gridDim.x * num_threads_in_a_block;
- int row_offset = blockIdx.y * num_threads_in_a_row;
- int gid = tid + block_offset + row_offset;
- printf("id=%d, blockIdx.x=%d, blockIdx.y=%d, value=%d\n", gid, blockIdx.x, blockIdx.y, input[gid]);
- }
- int main()
- {
- std::vector<int> h_data = {23, 9, 4, 53, 65, 12, 1, 33, 22, 43, 56, 4, 76, 81, 94, 32};
- int array_size = h_data.size();
- int array_byte_size = sizeof(int) * array_size;
- for (int i = 0; i < array_size; i++)
- printf("%d ", h_data[i]);
- printf("\n\n");
- int* d_data;
- cudaMalloc(&d_data, array_byte_size);
- cudaMemcpy(d_data, h_data.data(), array_byte_size, cudaMemcpyHostToDevice);
- dim3 block(2, 2);
- dim3 grid(2, 2);
- unique_gid_calculation_2d_2d << < grid, block >> > (d_data);
- cudaDeviceSynchronize();
- cudaDeviceReset();
- return 0;
- }
核对打印结果,可以看到索引正确。
- 23 9 4 53 65 12 1 33 22 43 56 4 76 81 94 32
- id=0, blockIdx.x=0, blockIdx.y=0, value=23
- id=1, blockIdx.x=0, blockIdx.y=0, value=9
- id=2, blockIdx.x=0, blockIdx.y=0, value=4
- id=3, blockIdx.x=0, blockIdx.y=0, value=53
- id=12, blockIdx.x=1, blockIdx.y=1, value=76
- id=13, blockIdx.x=1, blockIdx.y=1, value=81
- id=14, blockIdx.x=1, blockIdx.y=1, value=94
- id=15, blockIdx.x=1, blockIdx.y=1, value=32
- id=8, blockIdx.x=0, blockIdx.y=1, value=22
- id=9, blockIdx.x=0, blockIdx.y=1, value=43
- id=10, blockIdx.x=0, blockIdx.y=1, value=56
- id=11, blockIdx.x=0, blockIdx.y=1, value=4
- id=4, blockIdx.x=1, blockIdx.y=0, value=65
- id=5, blockIdx.x=1, blockIdx.y=0, value=12
- id=6, blockIdx.x=1, blockIdx.y=0, value=1
- id=7, blockIdx.x=1, blockIdx.y=0, value=33
目前的这种寻址方式,是依据执行配置进行的,思路很自然:按照 grid、block、thread 的层次进行“编址”。所以 thread 内部的索引是连续的。
如果想跨 block 进行索引,比如第一个 block 里的第一行是 0 1 ,第二个 block 的第一行是 2 3。目前没想到怎么办,也可能根本就不行,留作问题。