
顶点处理与绘图命令 - 绘图命令
第七章的标题叫深入探索。所以按照着色阶段,首先会“深入探索”顶点着色阶段。这篇文章系统地介绍绘图命令。
我们之前一直使用的绘画命令是 glDrawArrays(),它是一个非索引绘画命令。非索引的意思是依次画出顶点缓冲里的各个点。
索引绘图命令
非索引命令相对应的是索引命令,其实在之前我们学习 obj 格式的时候,已经接触过索引的概念了。在 obj 格式中首先会定义各个顶点,接着会用各个顶点编号组合定义成面,也就是索引。
索引最直观的好处是节省数据量,让我们结合程序来进一步说明。
如代码清单 1.1 所示,正方体有 8 个顶点,所以顶点只需使用 24 个浮点数(vertex_positions),即 96 个字节。索引面需要用到 36 个元素,这边是 short 类型,更加节省空间,但我们不妨使用 int 类型计算为 144 字节。索引共计用到 (24+36)*4=240 字节。
而之前的非索引的方式:6(个面)*2(个三角形)*3(个顶点)*3(个分量),即要用到 108 个浮点数,即 432 个字节。索引相较于非索引,数据量减少了接近一半。
- static const GLushort vertex_indices[] =
- {
- 0, 1, 2,
- 2, 1, 3,
- 2, 3, 4,
- 4, 3, 5,
- 4, 5, 6,
- 6, 5, 7,
- 6, 7, 0,
- 0, 7, 1,
- 6, 0, 2,
- 2, 4, 6,
- 7, 5, 3,
- 7, 3, 1
- };
- static const GLfloat vertex_positions[] =
- {
- -0.25f, -0.25f, -0.25f,
- -0.25f, 0.25f, -0.25f,
- 0.25f, -0.25f, -0.25f,
- 0.25f, 0.25f, -0.25f,
- 0.25f, -0.25f, 0.25f,
- 0.25f, 0.25f, 0.25f,
- -0.25f, -0.25f, 0.25f,
- -0.25f, 0.25f, 0.25f,
- };
- glCreateBuffers(1, &position_buffer);
- glBindBuffer(GL_ARRAY_BUFFER, position_buffer);
- glBufferData(GL_ARRAY_BUFFER,
- sizeof(vertex_positions),
- vertex_positions,
- GL_STATIC_DRAW);
- glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 0, NULL);
- glEnableVertexAttribArray(0);
- glCreateBuffers(1, &index_buffer);
- glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, index_buffer);
- glBufferData(GL_ELEMENT_ARRAY_BUFFER,
- sizeof(vertex_indices),
- vertex_indices,
- GL_STATIC_DRAW);
顶点数据的绑定流程和之前学习到的一样,但这边使用了一个首次遇到的 glVertexAttribPointer() 函数。它作为我们之前了解到的 glVertexAttribFormat()、glVertexAttribBinding()、glBindVertexBuffer() 这些底层函数的辅助函数,实现的功能是一样的。最后不要忘记使用 glEnableVertexAttribArray() 函数使能顶点属性。
索引数据的创建流程和普通缓冲一样,要注意将它绑定到 GL_ELEMENT_ARRAY_BUFFER。
索引数据绑定到 GL_ELEMENT_ARRAY_BUFFER。
铺垫这么久,终于介绍到需要使用的索引绘图命令了——glDrawElements()。当顶点缓冲和索引缓冲配置好之后,就可以在渲染函数里调用 glDrawElements 了。
- glDrawElements(GL_TRIANGLES, 36, GL_UNSIGNED_SHORT, 0);
glDrawElements() 函数的原型为
- void glDrawElements(GLenum mode,
- GLsizei count,
- GLenum type,
- const void *indices);
其中 mode 和 count 参数,与 glDrawArrays() 的含义一致。type 指示索引的类型,此例中是 short 类型。最后一个 indices 参数,含义暂不清楚,书中介绍的是绑定的索引缓冲内的偏移。具体不知道怎么偏移,但是偏移 0 肯定是最常规的情况,这边也是直接设置为 0。
实例化
有时候会遇到需要多次绘制同一对象的情况,比如绘制一片草坪。代码会近似如下:
- glBindVertexArray(grass_vao);
- for (int n = 0; n < number_of_blades_of_grass; n++)
- {
- SetupGrassBladeParameters();
- glDrawArrays(GL_TRIANGLE_STRIP, 0, 6);
- }
显卡绘制一棵草很容易,但当 number_of_blades_of_grass 很大的时候,绘制的时间占比可能和多次命令发送给显卡的传输时间占比接近。这章介绍的实例化渲染就是为了节省通讯传输的时间。
实例化渲染也有非索引和索引版本的函数:
- void glDrawArraysInstanced(GLenum mode,
- GLint first,
- GLsizei count,
- GLsizei instancecount);
- void glDrawElementsInstanced(GLenum mode,
- GLsizei count,
- GLenum type,
- const void *indices,
- GLsizei instancecount);
可以看到实例化函数就是在我们上一节学习到的函数基础上,多加了一个 instancecount 参数,它用来指示一次绘制多少个实例对象。即把循环从 CUP 上“移到了”显卡内部,从而节省了通讯的时间。
但是仅仅把循环移到显卡内部还存在一个问题:如果想要每个实例的属性参数不一样,每次都像代码清单 2.1 中调用 SetupGrassBladeParameters() 函数进行设置的话,还是存在通讯时间的浪费。
为了应对以上问题,我们看到 OpenGL 和实例化相关的一个内部变量——gl_InstanceID,这才是实例化的“精髓”。绘制第一个实例化对象时,gl_InstanceID 为 0,绘制之后的实例依次加 1,即最终到 instancecount-1。
我们以实例化草坪的例子,来看 gl_InstanceID 是如何被精心构造的。我们着重看代码清单 2.2 的顶点着色器程序部分,其余设置和之前学的大同小异。
在代码清单 2.2 中关注和 gl_InstanceID 相关的变量。可以看到 gl_InstanceID 的高低位被拆分成草坪的行列,同时位置的偏移量也使用 gl_InstanceID 作为种子。草的长度、弯曲度等依赖其位置,但其实也简介依赖于 gl_InstanceID。就是这样利用 gl_InstanceID,我们可以生成如图 1 这样随机的草坪。
- #version 420 core
- // Incoming per vertex position
- in vec4 vVertex;
- // Output varyings
- out vec4 color;
- uniform mat4 mvpMatrix;
- layout (binding = 0) uniform sampler1D grasspalette_texture;
- layout (binding = 1) uniform sampler2D length_texture;
- layout (binding = 2) uniform sampler2D orientation_texture;
- layout (binding = 3) uniform sampler2D grasscolor_texture;
- layout (binding = 4) uniform sampler2D bend_texture;
- int random(int seed, int iterations)
- {
- int value = seed;
- int n;
- for (n = 0; n < iterations; n++)
- {
- value = ((value >> 7) ^ (value << 9)) * 15485863;
- }
- return value;
- }
- vec4 random_vector(int seed)
- {
- int r = random(gl_InstanceID, 4);
- int g = random(r, 2);
- int b = random(g, 2);
- int a = random(b, 2);
- return vec4(float(r & 0x3FF) / 1024.0,
- float(g & 0x3FF) / 1024.0,
- float(b & 0x3FF) / 1024.0,
- float(a & 0x3FF) / 1024.0);
- }
- mat4 construct_rotation_matrix(float angle)
- {
- float st = sin(angle);
- float ct = cos(angle);
- return mat4(vec4(ct, 0.0, st, 0.0),
- vec4(0.0, 1.0, 0.0, 0.0),
- vec4(-st, 0.0, ct, 0.0),
- vec4(0.0, 0.0, 0.0, 1.0));
- }
- void main(void)
- {
- vec4 offset = vec4(float(gl_InstanceID >> 10) - 512.0,
- 0.0f,
- float(gl_InstanceID & 0x3FF) - 512.0,
- 0.0f);
- int number1 = random(gl_InstanceID, 3);
- int number2 = random(number1, 2);
- offset += vec4(float(number1 & 0xFF) / 256.0,
- 0.0f,
- float(number2 & 0xFF) / 256.0,
- 0.0f);
- vec2 texcoord = offset.xz / 1024.0 + vec2(0.5);
- float bend_factor = texture(bend_texture, texcoord).r * 2.0;
- float bend_amount = cos(vVertex.y);
- float angle = texture(orientation_texture, texcoord).r * 2.0 * 3.141592;
- mat4 rot = construct_rotation_matrix(angle);
- vec4 position = (rot * (vVertex + vec4(0.0, 0.0, bend_amount * bend_factor, 0.0))) + offset;
- position *= vec4(1.0, texture(length_texture, texcoord).r * 0.9 + 0.3, 1.0, 1.0);
- gl_Position = mvpMatrix * position;
- color = texture(grasspalette_texture, texture(grasscolor_texture, texcoord).r) +
- vec4(random_vector(gl_InstanceID).xyz * vec3(0.1, 0.5, 0.1), 1.0);
- }
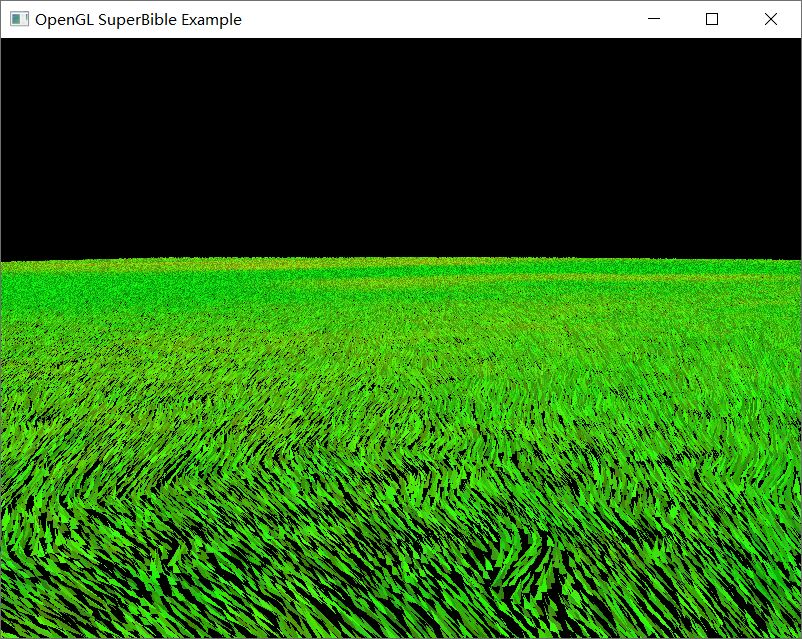
根据实例号获取数据
引入实例化后,我们可能会遇到一个需求问题:我们可能想要依据 gl_InstanceID 来索引传入的顶点数据,但是顶点数据默认是按绘制顶点顺序进行传递的。如代码清单 2.2 所示,我们想要实例中的点具有相同的颜色和位置偏移。
- #version 410 core
- layout (location = 0) in vec4 position;
- layout (location = 1) in vec4 instance_color;
- layout (location = 2) in vec4 instance_position;
- out Fragment
- {
- vec4 color;
- } fragment;
- void main()
- {
- gl_Position = (position + instance_position) * vec4(0.25, 0.25, 1.0, 1.0);
- fragment.color = instance_color;
- }
可以使用 glVertexAttribDivisor() 函数达到上述目的。看到代码清单 3.2,square_vertices 数组是四个顶点,instance_colors 数组是四个实例各自对应的颜色,instance_position 数组是四个实例各自对应的位置偏移,后续的缓冲设置步骤和之前学习的一样。主要是多了一步 glVertexAttribDivisor 设置,其原型为:
- void glVertexAttribDivisor(GLuint index, GLuint divisor);
第一个参数是属性的下标位置,第二个参数是属性除数。设置了之后,对应的属性就会按照 [instance/divisor]+baseInstance 的公式进行索引。此处是按实例号逐一索引,所以将除数设置为 1。如果除数为 0,则按照原先的顶点属性数组进行索引。还有需要说明的一点是,公式中的 baseInstance 是类似 glDrawArraysInstancedBaseInstance() 这种函数名后缀指定的,没有指定的话默认为 0。
套 [instance/divisor]+baseInstance 公式就可以。
- static const GLfloat square_vertices[] =
- {
- -1.0f, -1.0f, 0.0f, 1.0f,
- 1.0f, -1.0f, 0.0f, 1.0f,
- 1.0f, 1.0f, 0.0f, 1.0f,
- -1.0f, 1.0f, 0.0f, 1.0f
- };
- static const GLfloat instance_colors[] =
- {
- 1.0f, 0.0f, 0.0f, 1.0f,
- 0.0f, 1.0f, 0.0f, 1.0f,
- 0.0f, 0.0f, 1.0f, 1.0f,
- 1.0f, 1.0f, 0.0f, 1.0f
- };
- static const GLfloat instance_position[] =
- {
- -2.0f, -2.0f, 0.0f, 0.0f,
- 2.0f, -2.0f, 0.0f, 0.0f,
- 2.0f, 2.0f, 0.0f, 0.0f,
- -2.0f, 2.0f, 0.0f, 0.0f
- };
- glCreateVertexArrays(1, &square_vao);
- glBindVertexArray(square_vao);
- GLuint offset = 0;
- glCreateBuffers(1, &square_buffer);
- glBindBuffer(GL_ARRAY_BUFFER, square_buffer);
- glBufferData(GL_ARRAY_BUFFER, sizeof(square_vertices) + sizeof(instance_colors) + sizeof(instance_position), NULL, GL_STATIC_DRAW);
- glBufferSubData(GL_ARRAY_BUFFER, offset, sizeof(square_vertices), square_vertices);
- offset += sizeof(square_vertices);
- glBufferSubData(GL_ARRAY_BUFFER, offset, sizeof(instance_colors), instance_colors);
- offset += sizeof(instance_colors);
- glBufferSubData(GL_ARRAY_BUFFER, offset, sizeof(instance_position), instance_position);
- glVertexAttribPointer(0, 4, GL_FLOAT, GL_FALSE, 0, 0);
- glVertexAttribPointer(1, 4, GL_FLOAT, GL_FALSE, 0, (GLvoid*)sizeof(square_vertices));
- glVertexAttribPointer(2, 4, GL_FLOAT, GL_FALSE, 0, (GLvoid*)(sizeof(square_vertices) + sizeof(instance_colors)));
- glEnableVertexAttribArray(0);
- glEnableVertexAttribArray(1);
- glEnableVertexAttribArray(2);
- glVertexAttribDivisor(1, 1);
- glVertexAttribDivisor(2, 1);
按照公式,我们可以按图 2 所示的效果进行核对验证,的确满足我们的预期。同时这几个属性数组恰好大小一致,我们把颜色的属性除数改成 0,效果如图 2 所示,以此对比加深对 glVertexAttribDivisor() 函数的理解。
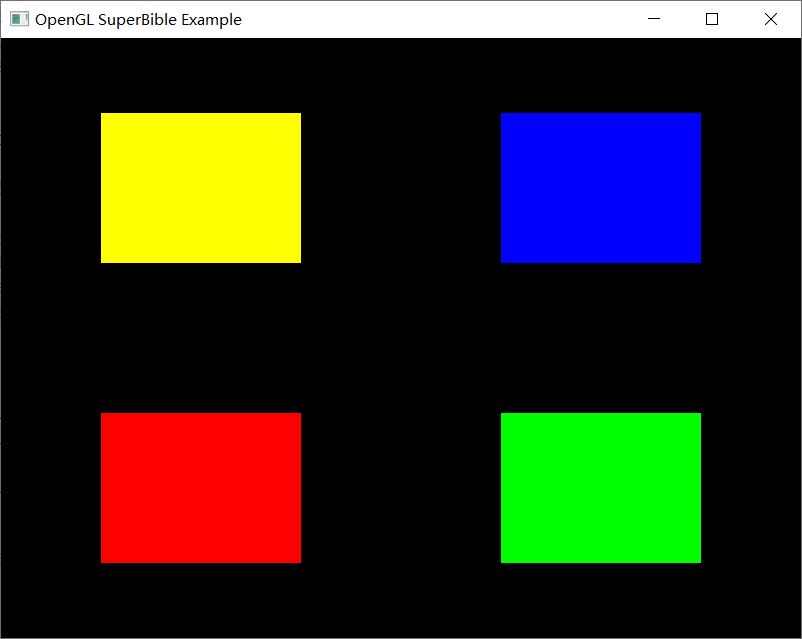
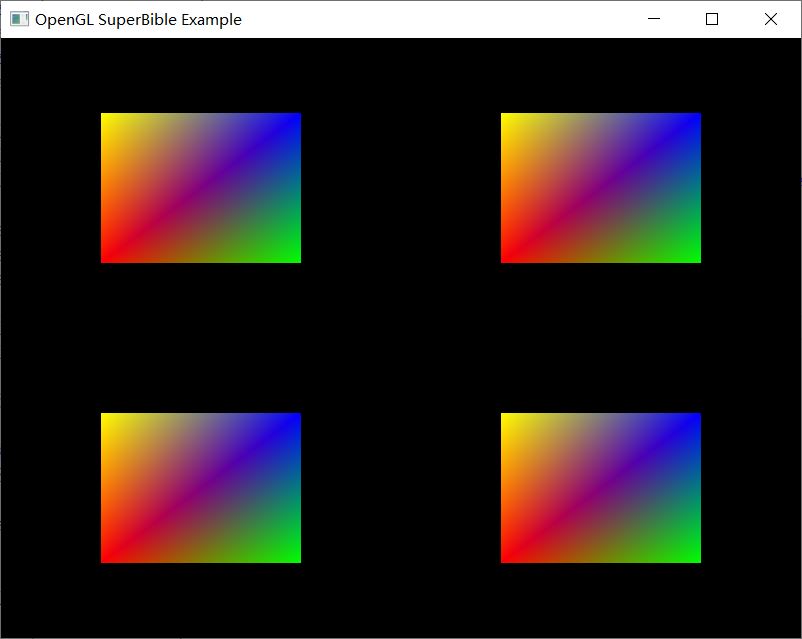
间接绘制
实例化绘制是为了解决 CPU 和显卡频繁通信的问题,但实例化是建立在同一个绘制对象上的。那如果是要频繁绘制多个不同的对象要怎么办呢?这就引入了这节的间接绘制。间接绘制的概念理解上很简单,既然调用函数通讯频繁,那我们就把所有需要的绘制指令先通过缓存的方式一次性传递给显卡,之后绘制的时候显卡直接从缓冲中取就可以了。而绘制函数的调用就是参数不同,所以“绘制指令”的存在方式就是一段参数集合。
先看到间接函数的原型:
- void glDrawArraysIndirect(GLenum mode, const void *indirect);
也有索引绘制版本的:
- void glDrawElementsIndirect(GLenum mode,
- GLenum type,
- const void *indirect);
前几个参数都和之前的绘制函数一致,新认识的是最后一个 indirect 参数。它就是所说的“参数集合”,比如 glDrawArraysIndirect() 对应的 indirect 参数缓存布局为:
- struct DrawArraysIndirectCommand
- {
- GLuint count;
- GLuint primCount;
- GLuint first;
- GLuint baseInstance;
- };
glDrawArraysIndirect() 和 glDrawElementsIndirect() 函数只能完成一条绘制指令,真正强大的是完成多条绘制指令的函数,它们多了一个 drawcount 参数,指示绘图指令的条数:
- void glMultiDrawArraysIndirect(GLenum mode,
- const void *indirect,
- GLsizei drawcount,
- GLsizei stride);
- void glMultiDrawElementsIndirect(GLenum mode,
- GLenum type,
- const void *indirect,
- GLsizei drawcount,
- GLsizei stride);
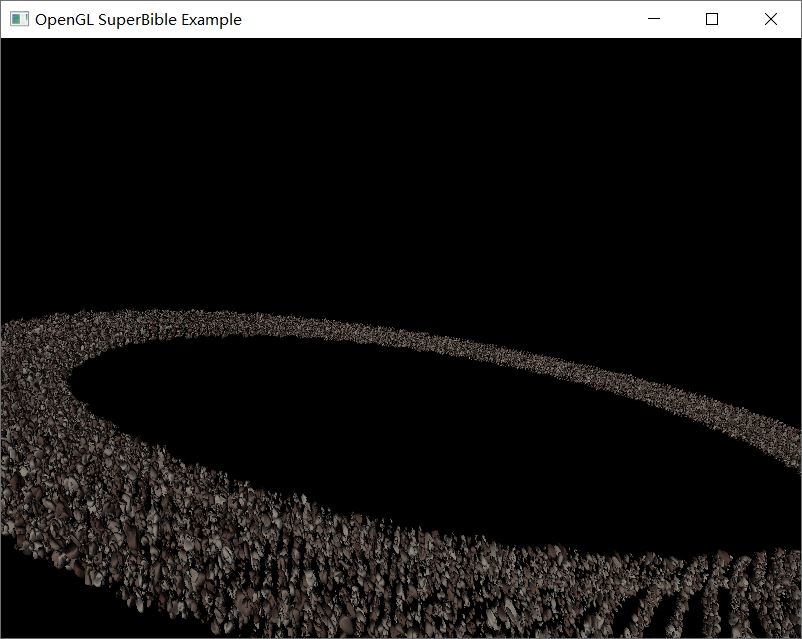
书上有一个小行星带(感觉应该是陨石带🤪)的例子,其中绘制了 100 个不同物体对象共计 50000 次。具体绘制细节这边就不细说了,我们直接看到代码清单 4.1 的间接绘图缓冲设置。
小行星顶点数据的加载逻辑在 object.load() 中,asteroids.sbm 中包含了 100 个不同的小行星模型,后续我们通过偏移(first)和顶点数量(count),从缓冲中指定绘制。object.get_sub_object_info() 可以获取不同模型的偏移和顶点数量信息。图 4 是一百个中的第一个小行星模型,可以稍微感受一下。
- object.load("asteroids.sbm");
- glCreateBuffers(1, &indirect_draw_buffer);
- glBindBuffer(GL_DRAW_INDIRECT_BUFFER, indirect_draw_buffer);
- glBufferData(GL_DRAW_INDIRECT_BUFFER,
- NUM_DRAWS * sizeof(DrawArraysIndirectCommand),
- NULL, GL_STATIC_DRAW);
- DrawArraysIndirectCommand* cmd = (DrawArraysIndirectCommand*)glMapBufferRange(
- GL_DRAW_INDIRECT_BUFFER,
- 0,
- NUM_DRAWS * sizeof(DrawArraysIndirectCommand),
- GL_MAP_WRITE_BIT | GL_MAP_INVALIDATE_BUFFER_BIT);
- for (i = 0; i < NUM_DRAWS; i++)
- {
- object.get_sub_object_info(i % object.get_sub_object_count(),
- cmd[i].first, cmd[i].count);
- cmd[i].primCount = 1;
- cmd[i].baseInstance = i;
- }
- glUnmapBuffer(GL_DRAW_INDIRECT_BUFFER);
后续代码清单 4.1 中的第 3 至 7 行,创建绘图缓冲,以及分配相应缓冲的大小。第 9 行进行缓冲映射,用于后续写入操作。第 15 至 21 行就是设置绘图缓冲的操作,分别设置不同的物体对象(偏移和顶点数量)以及实例数(1 个)和基准实例号(用于索引 draw_index 顶点属性)。
最终的运行效果如图 5 所示。需要说明的是,对比于不使用间接绘制的直接绘制,本地实验看起来并没有慢多少,这个现象先做记录,待后续有机会再了解和解释。
总结
这一章介绍了索引绘图指令;介绍了能更高效绘制同一对象的实例绘制,同时介绍了如果按实例号索引顶点数据;最后介绍了间接绘制,它直接把绘图指令指定在缓冲中,可以一次性指定多条绘制命令。